今回は計算量の観点にも注意を払ったTransformerを用いた画像分類モデルであるHaloNetを提案した論文について紹介します。
出典 : https://arxiv.org/abs/2103.12731
背景
Transformerが画像分野でも成果をあげつつありますが、Transformerは系列長Nに対して計算量がO(N^2)となるため、高解像度の画像に対して計算時間が長くなるという欠点があります。
計算量を抑えるため、画像全体に対してAttentionを計算するのではなく、ある程度の局所領域を区切ってその内部でのみAttentionを計算するという対処法が考えられます。
こういった局所的Attentionでも、どのように局所領域を区切るかといった問題は発生します。また効率的な計算のためにはメモリアクセスなどの要素も考慮する必要があります。
今回紹介する論文はそういう問題に対して一つの回答を与えるモデルを提案し、CNNでのSOTAモデルに近い計算効率で性能も良いTransformerベースのモデルを構築しています。
詳しい手法を見てみましょう。
HaloNetの手法
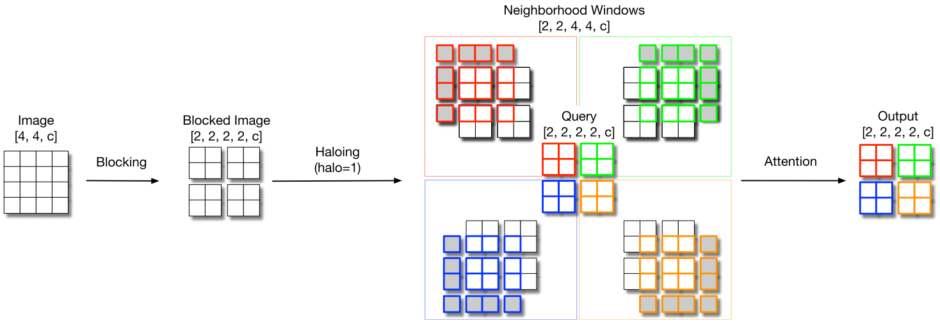
HaloNetのコアとなる考え方は以下で示すBlocked Local Attentionです。
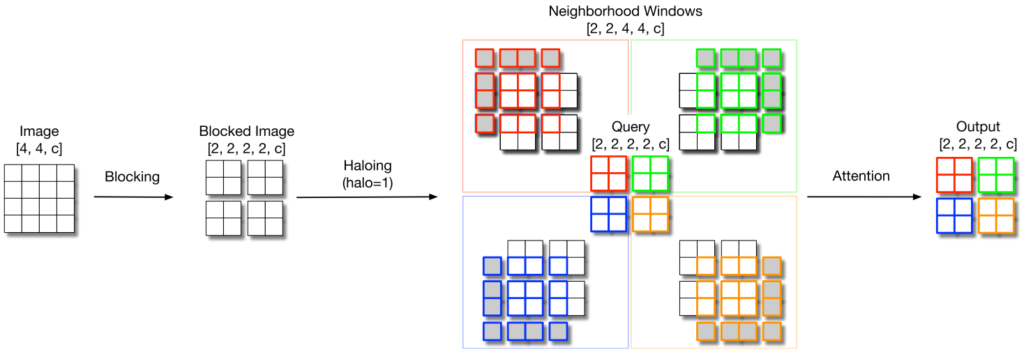
画像を適当なサイズのブロックに分け、周りにPadding(Halo : 後光)を付け加えた後に、ブロックについてAttentionを計算します。実際に変換する部分と、そのための付加情報を区別しているのが興味深い発想です。
CNNが1ピクセルごとにズラしながら計算が必要であるのに対して、この方法によるAttentionであれば複数ピクセルに対して一度に計算できる点で効率的です。
またCNNモデルで多くあるようなダウンサンプリングが必要な場合は、従来であればプーリングなどが使われていましたが、Transformerを用いてブロック内で計算する対象を1ピクセルに絞ることで実現できます。

先と同じ近傍(パディングされた領域)を用いることで、同じデータを使い回すことができ、メモリアクセスの効率が良くなるといった工夫も盛り込まれています。
全体として既存のCNNの徐々に解像度を落としていくネットワーク構造と揃えて、以下のように積み重ねます。

bがローカルブロックの幅、hがパディングの幅です。実験ではいくつかのモデルを検証していますが、これらは14×14(b = 8、h = 3)から18×18(b = 14、h = 2)の範囲となります。CNNの3×3と比べると1回の操作での受容野が広くなっています。
実験結果
ImageNetのスクラッチ学習においてEfficientNetをわずかに上回る性能を示しています。横軸にパラメータ数、縦軸にTop-1精度を示した図が以下となります。
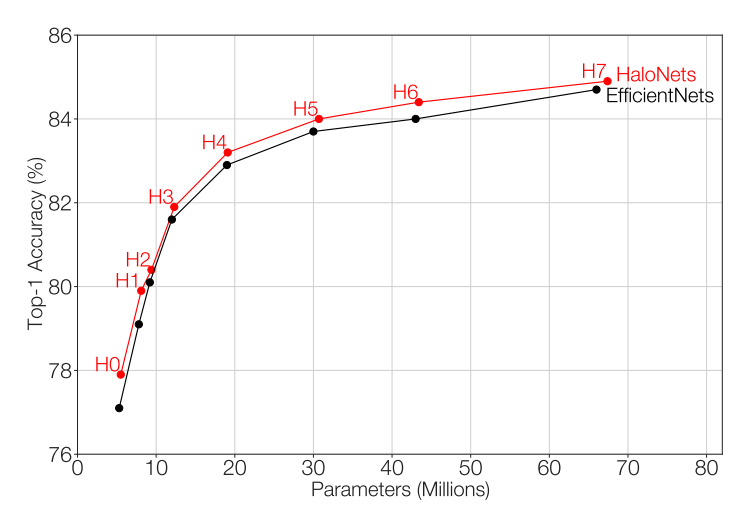
パラメータ数で見ると性能が良い結果となっています。これはAttentionブロックではクエリ、キー、バリューのそれぞれは重み共有ができているので、CNNに比べてパラメータを増やさないまま受容野を増やせるAttentionの利点が出ているものです。
一方で、学習に必要な計算時間として見るとまだ多くの時間がかかることは確かです。
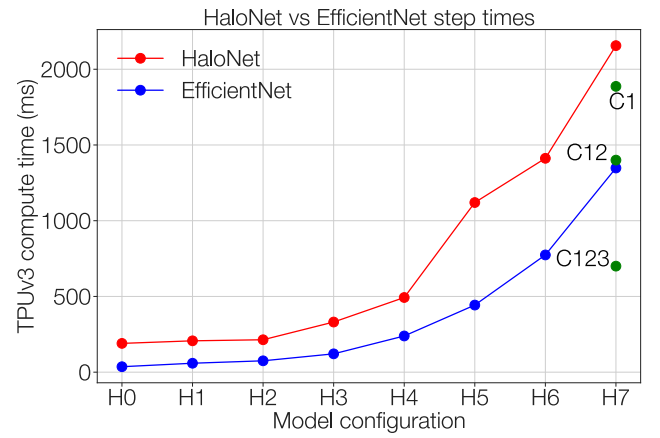
CNNなどがGPU・TPU上の計算において効率化されているのに対して、画像に対するTransformerは出始めたばかりなのでまだそういった点が十分に調整されていないという面もあるとは思います。
既存のCNNモデルと構造を揃えた面があるため、その他物体検出やセマンティックセグメンテーションにも使用して良い結果を出していますが、ここでは割愛します。
また提案モデルの直接的な性能検証からは外れるのですが、ResNet-50の畳み込みを完全にLocal Attentionに置き換えたモデルを用いて、正則化手法を加えたときの性能向上具合を検証しています。
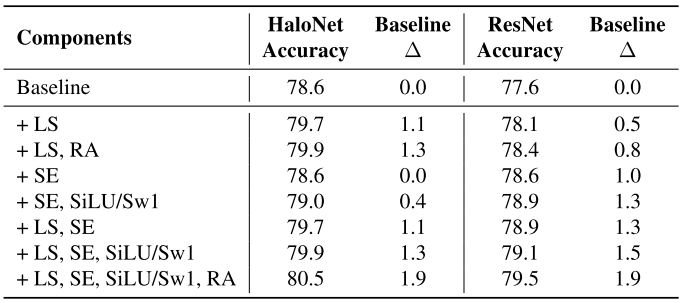
HaloNetではLS(Label Smoothing)とRA(Random Augmentation)を入れた際の伸びが大きく、ResNetでは加えてSE(Squeeze-and-Excitation)モジュールを入れることが重要になります。AttentionモジュールがSEモジュールと同様、チャンネル方向の情報統合を行っていることを示唆しています。
所感
局所的な特徴抽出を階層的に重ねる一般的なCNNのやり方は、計算効率も考えて洗練されたものであるため、大枠として今後も残っていくのだとは思います。CNNにおける3×3のフィルタを置き換える形で、ある程度の領域で区切ったLocal Attentionを用いるのがTransformerの利用方法として現実的なものだと感じます。今後もこの方向で発展が見られるのではないでしょうか。広く使われることで実装面等でも徐々に最適化がなされていくと考えると、既存の技術と互換性が高いやり方で徐々に置き換えられることは普及のために必要になってくるのだと思います。
本題からはやや外れるのですが、Transformerを使う利点として、Introductionにおいて触れられていた「他データとの統合が楽になる」という点は重要に思われます。速度や性能の意味でCNNに劣るとしても、自然言語処理との融合などマルチモーダル状況において取り回しがしやすいなら採用する価値はあると思われます。(一方でCNNを自然言語処理に使うなどの方向性もあるため、必ずしもマルチモーダル状況においてTransformerが有利とも限らないとは思います。)
やはり統一的なモデルというものには惹かれる面があるので、今後もTransformerには期待したいところです。