今回はTransformerを用いて画像のセマンティックセグメンテーションタスクで高い性能を示したSETRという手法を提案する論文について紹介します。
出典 : https://arxiv.org/abs/2012.15840
前書き
画像のセマンティックセグメンテーションタスクは、画像中のどこになにが写っているのかを判別するタスクです。一般的にピクセルごとのクラス分類として実現されます。
このタスクでは、写っている物体の意味的な情報と細かい境界情報の両方を考慮する必要があるため、大局的な特徴抽出と局所的な特徴抽出の両方が重要になります。
今までのところ、多くの場合これはU-Netのようなスキップコネクションを用いたEncoder-Decoderモデルを用いて実現されてきました。CNNを重ねることで徐々に大局的な情報を統合しつつ、スキップコネクションを介して対応するEncoder部分からも情報を得ることで局所的な境界の情報も取得します。
一方、Vision Transformer(https://openreview.net/forum?id=YicbFdNTTy)を筆頭に、近年では画像処理分野でもTransformerが成果をあげつつあります。その流れを受け、今回紹介する論文ではTransformerをセマンティックセグメンテーションへと応用し、高い性能を示すことを明らかにしています。
SETRの手法
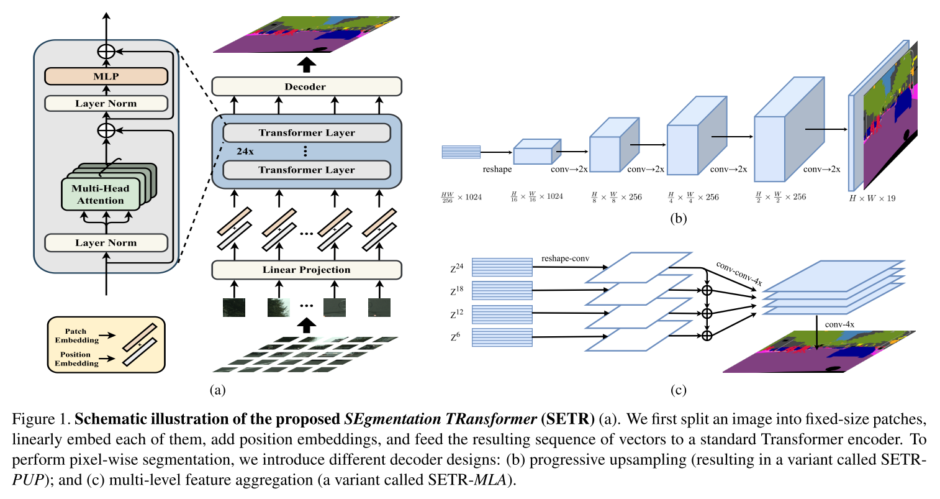
提案されたSETRは基本的にTransformerのみを用いたモデルです。以下が概要図となります。
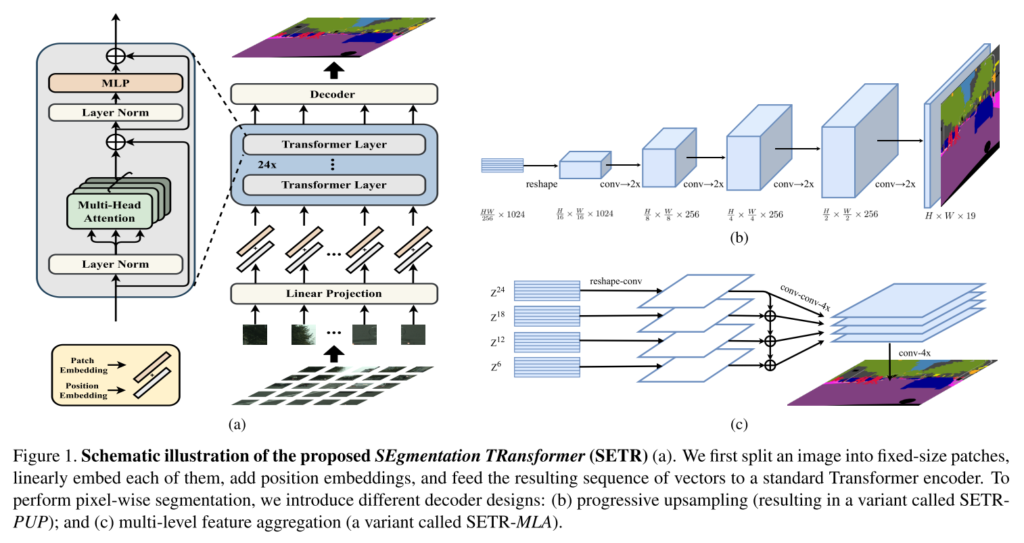
大きく分けるとEncoder部(画像中左)、Decoder部(画像中右)の2つから成ります。
まず、Encoder部はVision Transformerとほぼ同じ仕組みです。画像を適当な数のパッチにわけ、それらを1次元系列として並べた後、線形変換と位置エンコーディングを施して、十分な数のTransformerブロックへ入力します。
Decoder部では3種類のものを比較しています。
- Naive upsampling
- Encoderの出力を2層CNNにかけてピクセル単位のクラスタリングを行い、それを元画像のサイズへバイリニア補間で復元するDecoder
- Progressive Upsampling(PUP)
- 図1-(b) CNNによるアップサンプリングを繰り返していくDecoder
- Multi-Level feature Aggregation(MLA)
- 図1-(c) Pyramid Networkのように、戻る方向へ途中段階の特徴を足し合わせながらCNNにかけていくDecoder
学習の工夫
学習には補助損失として、Transformerの途中ブロックに(最終的なDecoderとは別の)2層からなるDecoderを取り付け、そこからの分類結果で損失を計算するものを追加しています。これはPyramid Scene Parsing Network(https://arxiv.org/abs/1612.01105)で用いられているものです。
また、事前学習としてViTあるいはDeiTで学習されたパラメータでTransformer部分を初期化しています。この事前学習はとても重要で、ランダムパラメータからの学習では全然性能が出ない結果となっていました。
実験結果
3つのデータセットで実験を行っています。
- Cityscapes
- 都市の風景画像(自動車に備え付けられたカメラから得られた画像) 19クラス
- 学習用2975枚 検証用500枚 テスト用1525枚
- 画像サイズ2048×1024
- 学習用に荒くアノテーションされた19998枚の画像もあり
- ADE20K
- 150クラス
- 学習用20210枚 検証用2000枚 テスト用3352枚
- PASCAL Context
- 頻度の高い59クラス + 背景の計60クラスを使用
- 学習用4998枚 検証用5105枚
それぞれの結果を以下に示します。
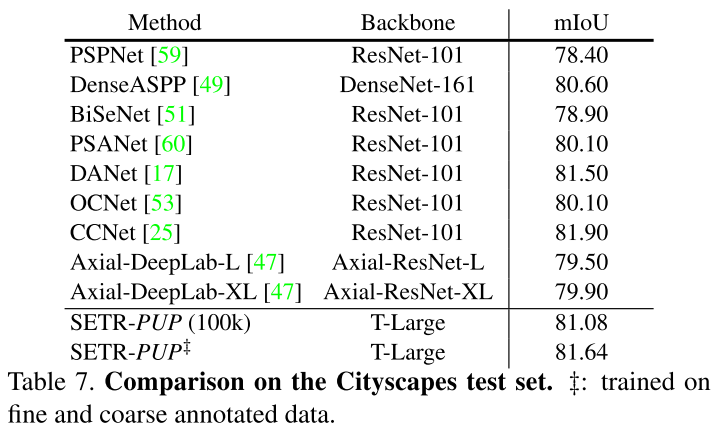
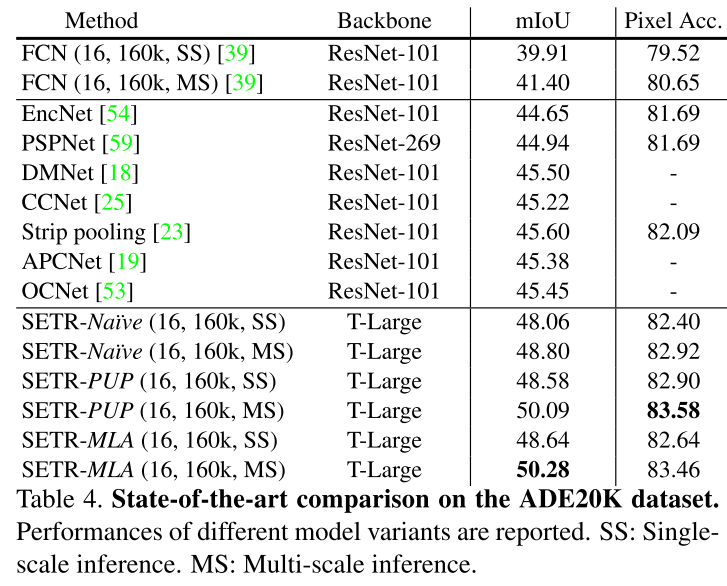
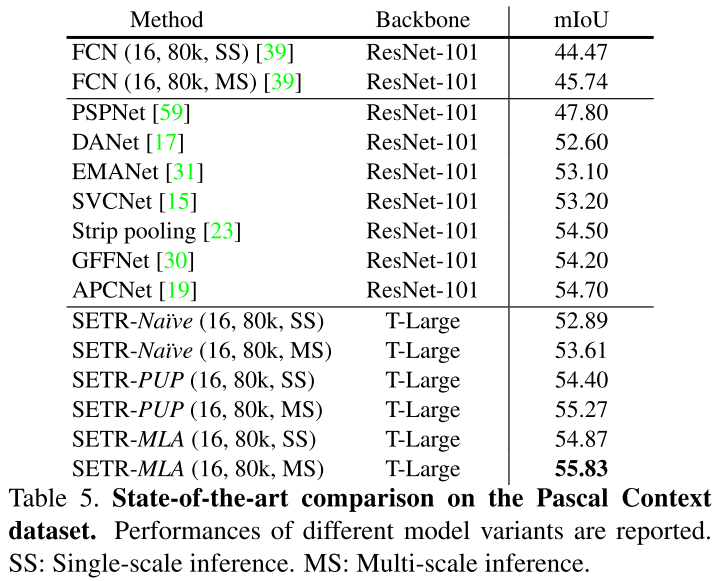
どれも最先端の手法に匹敵あるいは上回る結果となっていますが、特に既存手法を大きく上回ったのはADE20Kデータセットであり、その次にPascal Contexデータセットが続き、CityscapesデータセットではCCNetという手法にやや劣る結果でした。
所感
Vision Transformerが生み出した「Transformerが画像分野で使える」という流れに沿った研究だと思います。ViTの衝撃で慣れてしまったところはありますが、CNNを使わないEncoderで十分にセマンティックセグメンテーションが行える事実も驚きに値するものだと感じます。
提案手法はデータセットによりやや性能に差が出ていました。個人的な見解としては、これはデータセットの複雑さと関連しているのかもしれません。単純に分類するクラス数を比較すると、性能差が大きく出た順にそれぞれ150クラス、60クラス、19クラスとなっています。写っている物体や状況としての複雑さも概ねこの順番で降順になっていると思われます。
現状では、Transformerは難しいデータセットにも対応できるものの、その性能を引き出すためには事前学習含め十分な学習が必要なものとして捉えられるのではないかと思います。学習時間や推論時間の兼ね合いで、まだ他のモデルが適している状況も多々ありそうです。
とはいえ今後もTransformerに関する研究は多数行われていくでしょうし、その中で良い学習法やアーキテクチャが発見されることもあるでしょう。今後の発展から目が離せません。
以上、『Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers』の紹介でした。