今回はResMLPという、MLPのみを用いたネットワークで画像分類タスクを行い、CNNやTransformerモデルに比べてやや劣る程度の性能を達成した論文について紹介します。
出典 : https://arxiv.org/abs/2105.03404
背景
昨日紹介した論文MLP-Mixerと同様に、Transformerの勃興によって、画像分類におけるネットワーク構造の貢献度が再調査される流れになっています。ほぼ同時期に「MLPのみでSOTA手法に近い性能を達成できた」という主張の論文が出てきたのは興味深い点です。
詳しい手法を見てみましょう。
ResMLPの手法
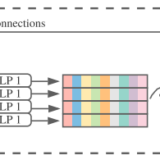
ResMLPは非常に単純で、画像をパッチ化したのち、MLPのみでできた残差ブロックを複数回通して、分類ヘッドに入力していくものとなっています。

画像中、Aと書かれているところは次に説明するAffオペレータであり、Tは転置を示します。
AffオペレータはLayer Normalizationの代わりとなるようなものであり、
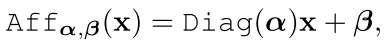
として表されます。xはd次元の入力ベクトルであり、α,βは学習可能なベクトルです。Diagは対角行列を意味するので、要するに要素ごとに線形変換を施しているということになります。入力Xとして行列を入力する場合は列ごとに線形変換を施すことになります。
パッチ数M(=N×N)、パッチの次元数dとし、入力Xはd×Mの行列とします。ブロック全体を式で表すと以下のようになります。
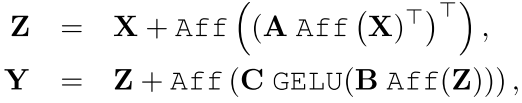
AがM×Mの重みを持つ線形変換であり、位置的な情報を統合します。Bは4d×d、Cはd×4d次元の重みを持ち、チャンネル方向の情報を一度大きくしてから絞ることで統合します。ここはTransformerの後半で使われるものと同じです。
全体としてMLP-Mixerとかなり近い構造ではあります。全結合層が1層か2層か、活性化関数をどの程度多く挟むか、Layer Normの代わりに列ごとの線形変換が入っているくらいの違いでしょうか。
実験結果
標準的なImageNet-1kを用いて実験を行っています。
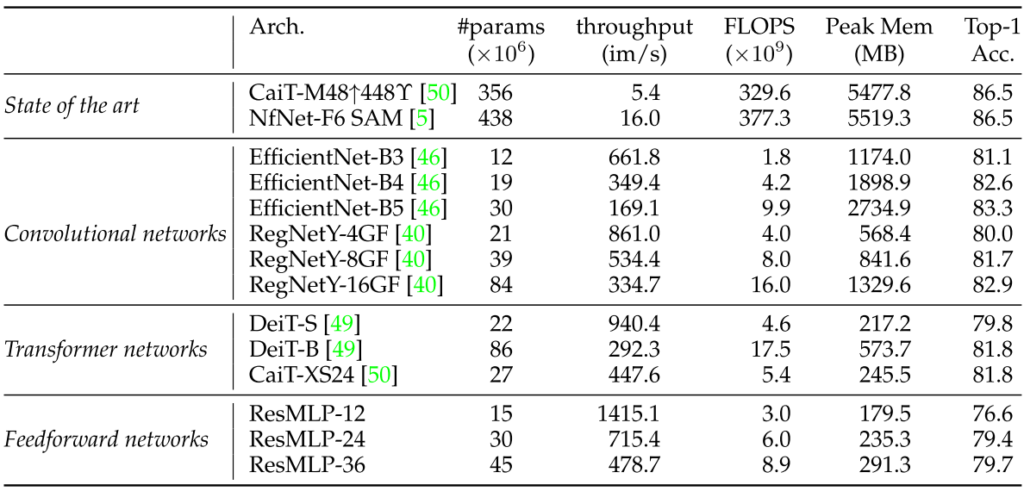
FLOPSが同程度のTransformer系統のネットワークとはかなり良い勝負の性能となっています。とはいえやはり上回るといった数値にはなっていません。
MLP-Mixerと同様に、学習で得られた重みの可視化も行われています。線形変換Aについての中央6×6に対応する部分について、重みの大きさを可視化したものが以下となります。

浅い層では近傍や線状など対応する位置的部分がはっきりわかりますが、Layer20などになると様々な位置から情報を取得していることがわかります。
所感
やはりMLPのみでもそれなりに良い性能へ到達するという主張の論文ではありましたが、そうはいってもCNNとの性能差も残る結果ではありました。
論文として目立つ部分ではないのですが、近年では学習方法の改善が多く発達しているのだと思われます。そういった細かい工夫の結果、MLPのみでも学習ができるようになっているのではないでしょうか。Revisiting ResNets(https://arxiv.org/abs/2103.07579)などの論文も出ており、学習方法自体の改善に注目するべきだと感じる点もでてきました。