今回はDeepLabv3+というモデルを提案する論文を紹介します。
出典 : https://arxiv.org/abs/1802.02611
背景
現在のセマンティックセグメンテーションはCNNのみを用いたモデルで行われることが一般的ですが、構造としては大きく2通りに分けられます。一つは空間的なピラミッド型プーリングを行うものであり、PSPNet、DeepLabなどがその代表例です。もう一つはEncoder-Decoder形式であり、U-Netなどがその代表例です。
ピラミッド型プーリングを使う場合では様々な解像度の特徴をまとめられるので、豊富な情報を取得できます。一方、Encoder-Decoder形式ではEncoderの同サイズ部分からスキップコネクションを繋げることで、物体の細かい境界を検知しやすい性質があります。
今回の論文では両者を組み合わせていいとこ取りをしよう、というものになっています。またCNN系の発展であるXceptionモジュールも使うことでとても良い性能が得られた、という主張になっています。
詳しい手法を見ていきましょう。
DeepLabv3+の手法
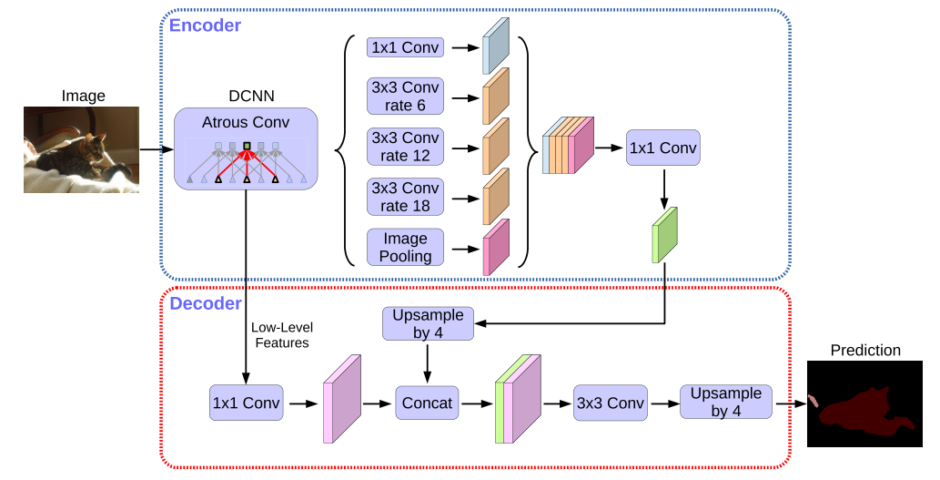
DeepLabv3+の全体図は以下のようになっています。
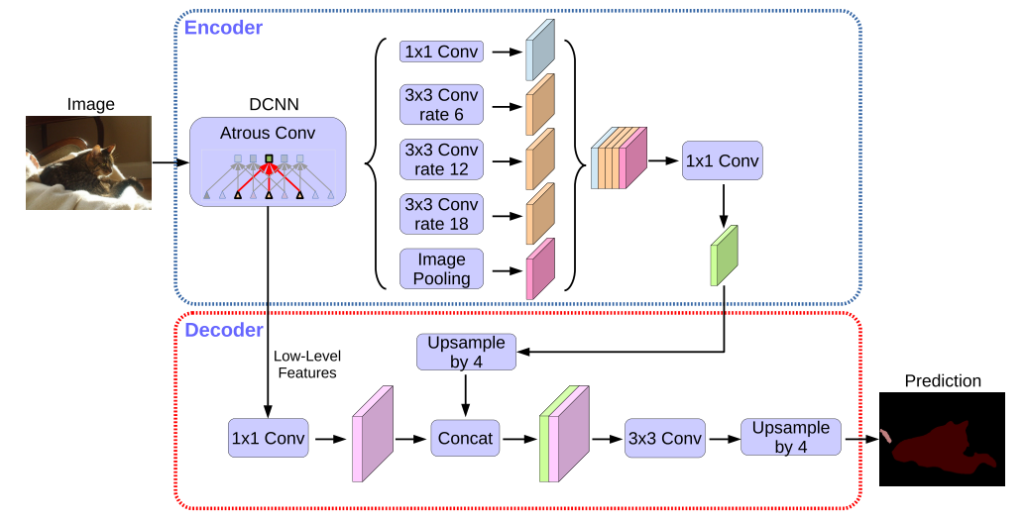
PSPNetなどで様々な解像度でプーリングを行う部分において、プーリングの代わりにArtous Convというものを用いています。またEncoder-Decoderのようなスキップコネクションも利用した構造となっています。
エンコーダ部分ではXceptionモジュールを利用しています。以下、Artous ConvとXceptionモジュールについて説明します。
Atrous Convolution
Atrous Convolutionは畳み込む位置を3×3ではなく、隙間を開けて取得する畳み込み手法です。これによりプーリング操作を用いずに、受容野を広げることができます。
これをDepthwise Convolutionという、各チャンネルごとに別の重みを用意して、各重みはそれぞれの1チャンネルのみを担当する手法と組み合わせます。
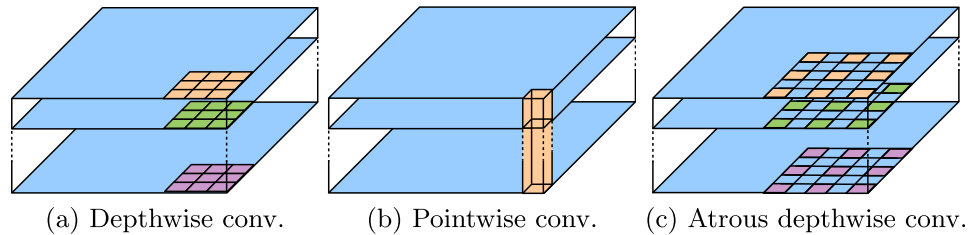
これをEncoderの最後、Spatial Pyramid Poolingにおけるプーリングの代わりに使うことで、様々な解像度の特徴を取得します。
Encoder : Xceptionモジュール
EncoderにはXceptionモジュールが使われています。Xceptionモジュール(https://arxiv.org/abs/1610.02357)はInceptionモジュールの考え方をより極端に推し進めた結果、Separable Convと同様のものに行き着いたというものになります。
まずInception Moduleは、様々な深さのCNNを並列に並べて擬似的に複数のネットワークを作り、学習によって最適なネットワークを獲得することを期待するものです。下図が一つのモジュールであり、これを何層も重ねていきます。
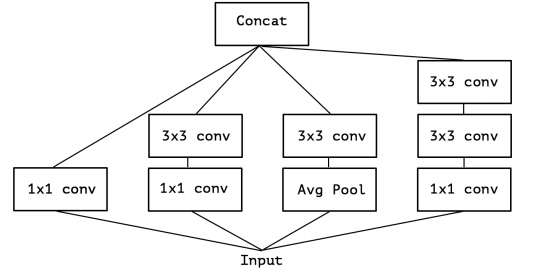
このモジュール部分を単純化すると、次のようになります。
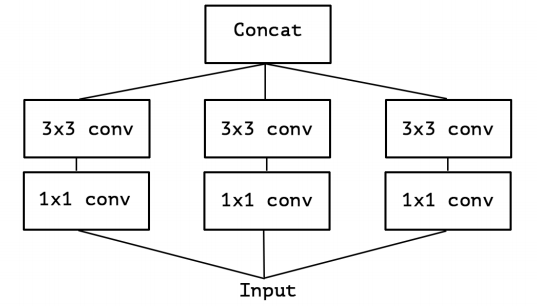
ここで発想を転換すると、このモジュールは一つの1×1Convを使い、3×3Convの入力前にチャンネル方向について分割したものとして見なせます(下図)。
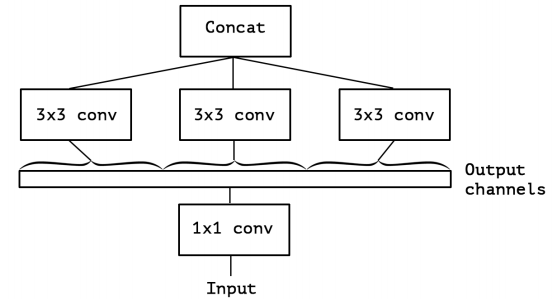
分割数を極端に増やして、3×3Convがそれぞれ1つのチャンネルだけ担当する状況を考えると、次のようになります。
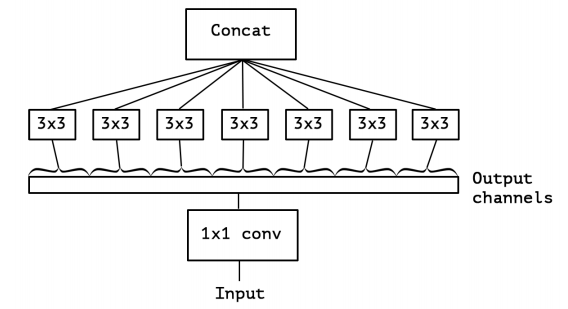
結局のところ、これはPointwise Conv→Depthwise Convであることがわかります。つまり、Separable Convと非常に近いものになります。違いは、普通のSeparable ConvはDepthwise→Pointwiseの順番で行うのに対して、XceptionモジュールでのSeparable ConvはPointwise→Depthwiseで行う点です。
DeepLabv3+として利用する際には、さらに3点の改良を加えています。
- Middle flowをより多くし、深いネットワークへ変更
- 最大プーリングをストライドありのSeparable Convへ変更
- 3×3のDepthwise Convごとにバッチ正規化とReLUを追加
結局、Encoderの構造は以下のようになります。
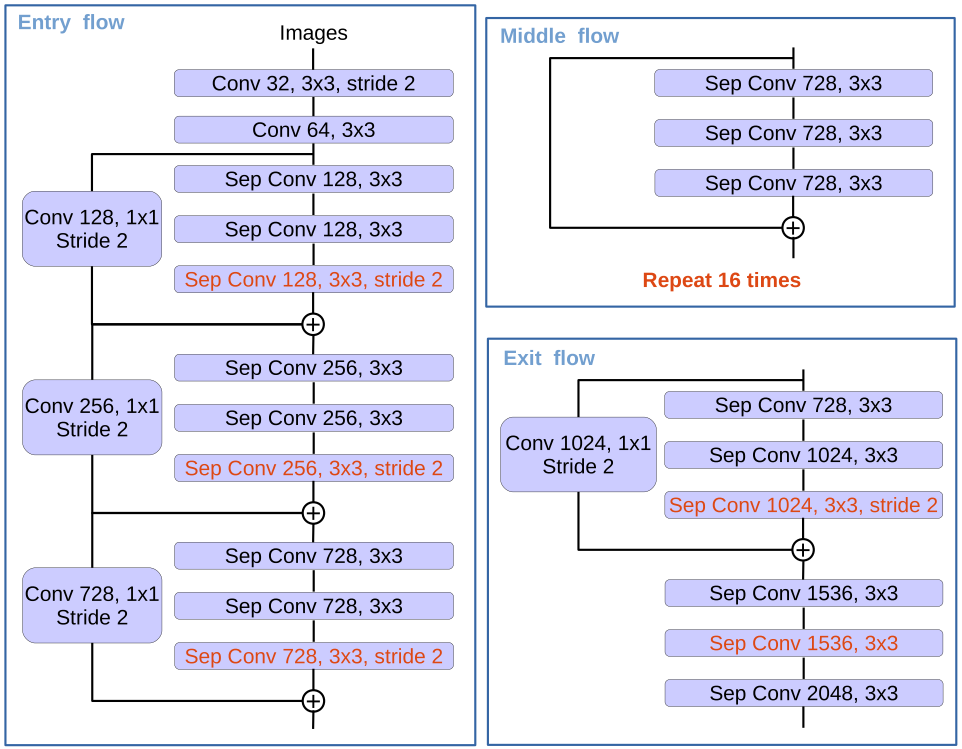
このEncoderの途中からDecoderへスキップコネクションを接続し、またEncoderの最後においてAtrous Convを用いた複数解像度のSpatial Pyramid Poolingを行います。
実験結果
各要素を切除するなど様々な条件で実験が行われていますが、ここでは割愛します。すべてを盛り込んだ最良の条件では、Pascal VOCデータセットに対してmIOU 89.0%を達成し、SOTAとなっています。
所感
様々な要素技術を詰め込んだ実践的な手法といった雰囲気を感じます。画像分野やセマンティックセグメンテーションにおける細かい知見を活かしたものであり、理解しきれていない部分もあったのですが、これ以上は論文を読むだけでなく実際にモデルを動かして問題へ対処してみないことには難しいようにも思えました。どういう点がどのように機能するのかという手法への理解と、ドメインの性質に対する理解の両立が、性能改善のためには欠かせないと感じます。