今回はMLP-Mixerという、全結合層(MLP)のみを用いた画像分類手法を提案する論文を紹介します。
出典 : https://arxiv.org/abs/2101.07172
背景
画像分野におけるニューラルネットワークは長らく畳み込みネットワーク(CNN)が良いとされてきましたが、近年ではTransformerがCNNに匹敵するほどの性能を示すようになっています。
Transformer系はCNNより受容野の広いネットワークですが、十分な事前学習を必要とする傾向にあります。一般化すると、自由度の高いネットワークを準備し、大量のデータを用いることで、CNNより良い特徴抽出が学習できる可能性があります。
紹介する論文ではMLP-Mixerという、全結合ネットワークのみからなるネットワークで画像分類を行う手法を提案しています。全結合であるのでCNNのような局所的な結合にとどまらない関係性を学習できる余地があります。
詳しい手法を見てみましょう。
MLP-Mixerの手法
画像処理ニューラルネットワークは以下の2つの操作を行っていると考えられます。
- 特定の空間的位置について特徴の混合(Channel Mixing)
- 異なる空間的位置についての特徴の混合(Token Mixing)
たとえばCNNでは1×1Convは(1)のみを、3×3Convなどでは(1),(2)の両方を行います。TransformerではSelf-Attention層で(1),(2)の両方を行い、その後のMLP層で(1)を行います。
提案手法のMLP-Mixerではこの(1)と(2)の操作を完全に分離することを目指します。MLP-Mixerの全体モデルは以下の図のようになります。
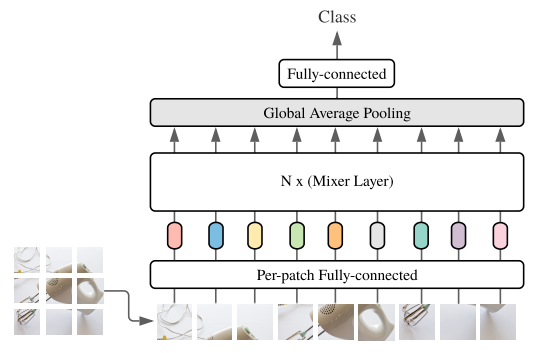
Vision Transformerなどと同じように、パッチ化した画像を入力とします。それをC次元の特徴ベクトルへ変換し、N個のMixer Layerに入力した後、Global Average Poolingを行って最終層へ入力し、分類を行います。
根幹となるMixer Layerは次のような構造になっています。

スキップコネクションやLayer正規化など細かい点はありますが、概ね
- Patch方向へ同じMLPブロックを適用(Token Mixing)
- チャンネル方向へ同じMLPブロックを適用(Channel Mixing)
をこの順で行っている構造です。「MLP1」「MLP2」として表されているMLPブロックは
- 全結合層
- GeLU活性化関数
- 全結合層
から成ります。
既存モデルとの比較
Channel Mixingは1×1のPointwise畳み込み、Token Mixingはパラメータ共有をしたDepthwise畳み込みと近いものであると見なすことができます。しかし、Token Mixingにおける畳み込み(MLP)パラメータを共有するのはDepthwise畳み込みではあまり行われていません。今回のMLP-MixerではどのチャンネルにおいてToken Mixingを行う際にも同じMLPブロックを用いており、これは実験的に性能を悪化させることはなかったとのことです。
入力の仕方や、ブロックを通じて特徴量の形が変わらないことはVision Transformerと似ていますが、Token Mixingにおいて位置情報は失われないため、MLP-Mixerでは位置エンコーディングは入れる必要がありません。
実験結果
ImageNet-21kで事前学習しImagNet-1kで評価しています。
比較手法としては最新のHaloNet(https://arxiv.org/abs/2103.12731)やVision Transformerを用いています。結果としては、MLP-Mixerはそういった手法にはやや届かない程度の精度となっています。
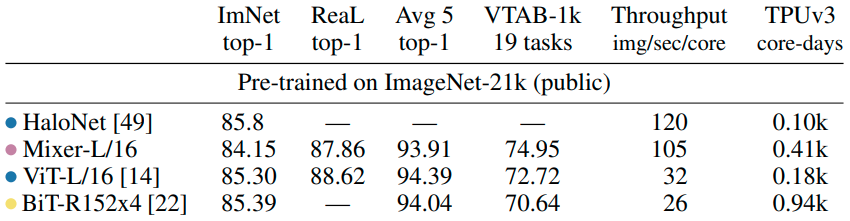
また学習時間もそれなりに長い時間が必要であることもわかります(最右列)。
論文には、学習されたToken-Mixingの重みを層が浅い順に左から並べて可視化した図も掲載されています。
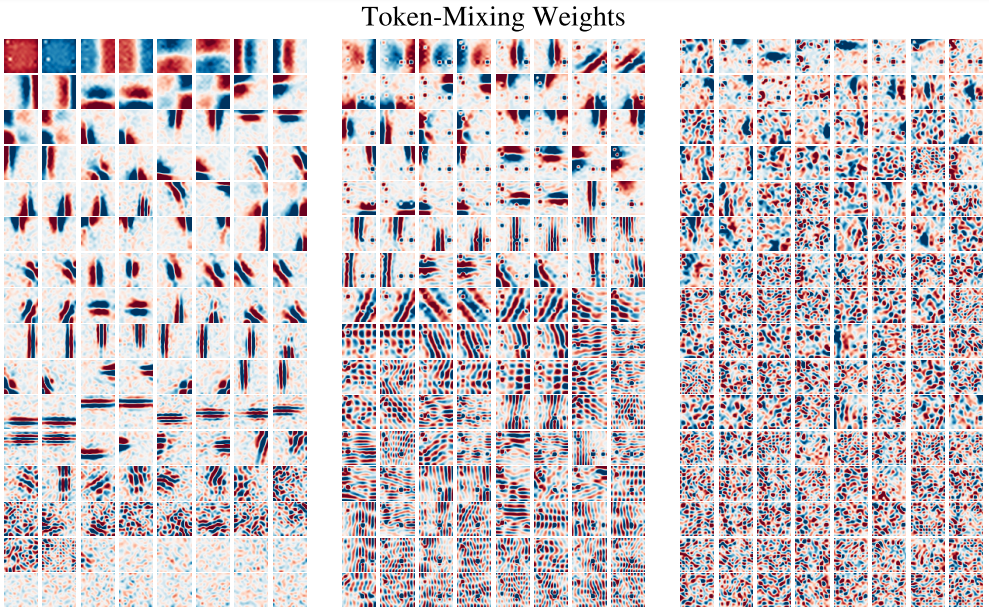
浅い層の方がはっきりと分かれて、ローカルな特徴抽出を行っていることがわかります。深い層では遠くから飛び飛びに情報を集めているようです。これらは一般的にCNNで見られる性質と類似しています。
所感
CNNは画像の重要特徴に局所性や位置不変性があるという知識を上手くネットワーク構造に反映させたものとして捉えられます。一方でTransformerや今回のMLP-Mixerには、ネットワーク的な制約を緩和し、代わりにそういった性質を大量の事前学習により獲得しているのではないかと考えられます。人手で作る効率的なバイアスを廃し、できるだけデータからの学習に任せるというのは深層学習全体の流れでもあるので今後も発展を期待したいところです。
しかし、学習の結果を可視化したものを見ると、浅い層では局所的な情報を捉えるようになっているため、CNNの設計の良さを示すことにもなっているのかと思われます。CNNの構造というのは一つのヒューリスティックではありますが、とても質の良いものであり、学習から上回ることが困難であったり、上回るとしても効率がものすごく改善するわけではないのかもしれません。しばらくのところ、実用的にはCNNが第一選択肢として有効であり続けるのだろうとは思います。