今回はSwin Transformerという手法を提案した論文について紹介します。これはTransformerベースのネットワークであり、コンピュータビジョンのバックボーンネットワーク(特徴抽出ネットワーク)として様々なタスクに対して汎用的に高い性能を示しています。
出典 : https://arxiv.org/abs/2103.14030
背景
Transformerを画像分野に適用する際には2つの問題点が考えられます。
まず1つ目として、認識する対象は画像中で様々な大きさを取ります。これは特に物体検出などで問題になり、様々な分解能で画像から物体を検出できる必要があります。既存のTransformerモデルでは画像を特定サイズのパッチに切り出して入力情報としていましたが、これでは大きさが固定になってしまうため上記の問題に対してやや不適当なところがありました。
また2つ目の問題として、Transformerに入力する系列長が(適当なパッチ化はあれど)おおむね画像サイズの2乗であるため、画像の解像度が高くなると系列が長大になってしまいます。やはり物体検出等では入力が高解像度である必要があるため、計算の効率化が欠かせません。
これら2つの問題に対応するため、Swin Transformerでは
- プーリングのようにデータの縦横幅を徐々に小さくしていく機構を用いる
- 効率化のためウィンドウを導入し、局所的なAttention計算を行う
という工夫を導入しています。以下、手法を詳しく見ていきます。
Swin Transformerの手法
Swin Transformerの全体図は以下のようになっています。
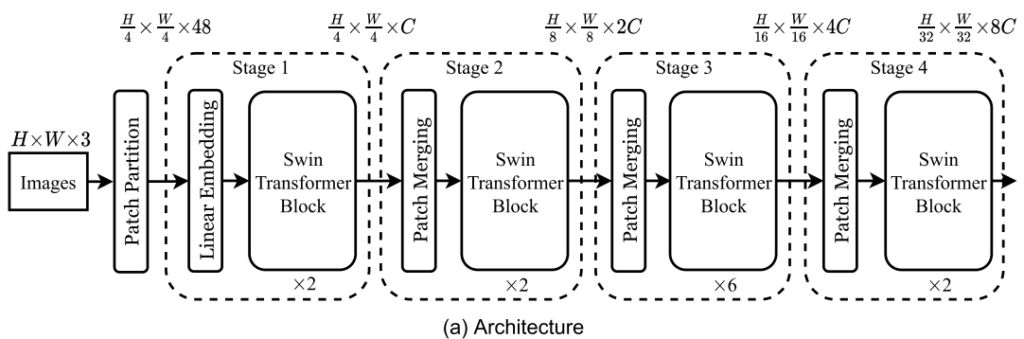
全体はStageの繰り返しであり、1つのStageではPatch Mergingを行った後、Swin Transformerブロック群へ入力していくことになります。
Patch Mergingでは単純に隣接2×2のパッチ(チャンネル数C)を1×1(チャンネル数4C)にまとめ、そこへ線形変換を行うことでチャンネル数を半分に減らします。CNNで言えばプーリングに近いものだと考えれば良さそうです。あるいはカーネルサイズ2×2のCNNをストライド2で適用しているとも見なせると思います。
Swin Transformerブロックでは、計算の効率化のため、Self-Attentionモジュールへパッチ全てを入力するのではなく、ウィンドウごとに区切ってそれぞれを独立に入力します。毎回同じ区切り方をしていると情報がその内部だけにとどまってしまうため、奇数個目のブロックでは単純に左上から区切りますが、偶数個目のブロックではウィンドウサイズの半分だけシフトした位置から区切りを作成します。
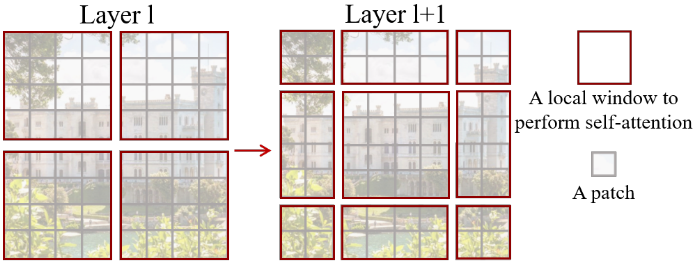
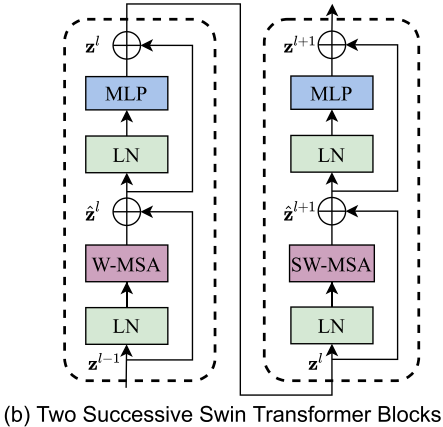
シフトした場合は小さいパッチ群が多くできてしまい、これを効率的に計算する手法も工夫があって面白いのですが、手法の本質的な部分ではないと判断してここでは割愛します。
また細かい話としては、各Self-Attentionモジュールにおいて、相対位置によるエンコーディングを行っています。これは学習可能のバイアスとして、ソフトマックス関数をかける直前で足されます。絶対位置ではなく相対位置でのエンコーディングを行った方が物体検出やセマンティックセグメンテーションでの結果が良かったようです。
実験結果
大きさのバリエーションとして、以下の4つを実験で使用しています
- Swin-T : C = 96, 各ステージの層数 = {2, 2, 6, 2}
- Swin-S : C = 96, 各ステージの層数 = {2, 2, 18, 2}
- Swin-B : C = 128, 各ステージの層数 = {2, 2, 18, 2}
- Swin-L : C = 192, 各ステージの層数 = {2, 2, 18, 2}
ImageNet-1Kのスクラッチ学習でEfficientNetなどと近い性能を示しています。Vision Transformerの学習に必要だったデータ拡張の繰り返しは、Swin Transformerでは使っていないとの記述がありました。
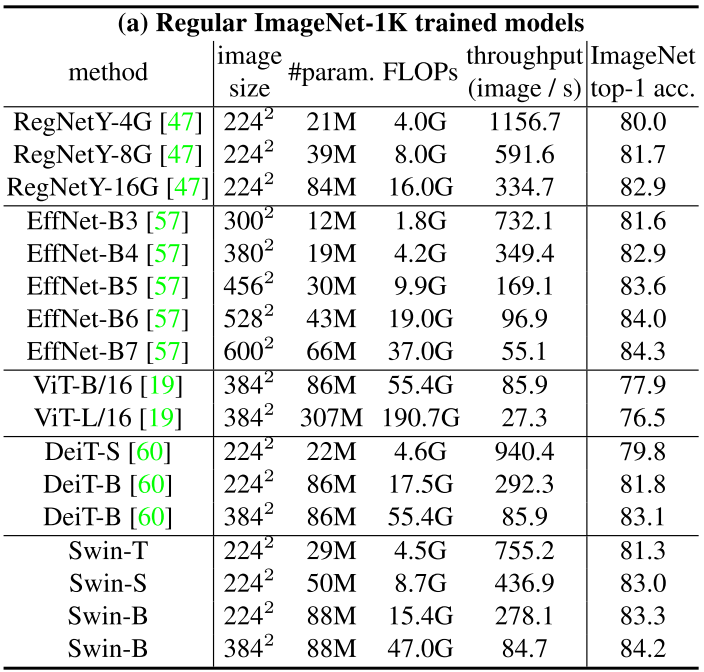
その他物体検出やセマンティックセグメンテーションでも良い結果が出ています。詳細は論文をご覧ください。
所感
Transformerの計算効率化を行うためにウィンドウで区切るという手法を提案していましたが、これにより部分的にはCNNに近くなり、1回のブロック中では局所的な情報しか見れなくなっています。受容野の広さと計算効率にはトレードオフがあり、さらにネットワークの深さとの兼ね合いもあるので、今後も様々な提案がなされていくのだと思います。
実験においてImageNetの1Kデータセットでスクラッチ学習が行われているようで、Transformer系がスクラッチからちゃんと学習できるのは珍しいように感じます。それも局所的な情報抽出に絞ったことで可能になったことなのかもしれません。
Patch Mergingのあたりなど、まだまだ工夫ができそうなところもあると感じます。今後もTransformer系の発展に期待です。